
Knowledge-Assisted Visual Analytics Methods for Time-Oriented Data – neue Methoden zur Erfassung von explizitem Expertenwissen und dessen Visualisierung vereinen menschliches Hintergrundwissen mit der Rechenstärke eines Computers.

Komplexe Datenmengen und ihre Darstellung
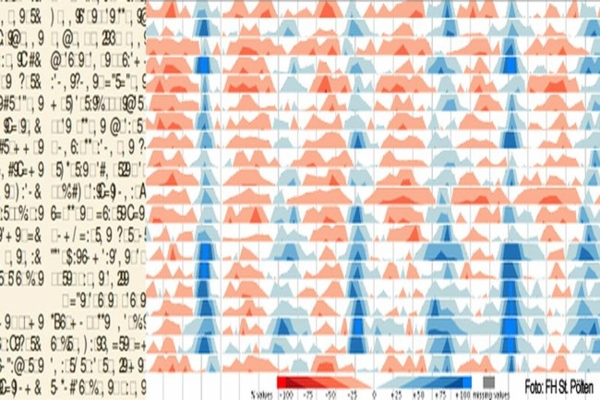
Um in praktischen Problemstellungen Erkenntnisse gewinnen zu können, muss meist mit großen, komplexen, unsicheren und widersprüchlichen Datenmengen gearbeitet werden. In solchen Szenarien kommen zeitorientierte Daten sehr häufig vor und spielen eine zentrale Rolle. Diese verlangen aber je nach Anwendungsdisziplin geeigneten Explorations- und Analysemethoden.
Derartige Spezialanwendungen sind für Einzelfälle realisierbar, zum Beispiel könnten bei Patienten- und Patientinnendaten die Normalwertebereiche je nach Geschlecht oder Alter angezeigt werden, bei Finanzdaten könnte die Zeitachse Wochenenden und Bankfeiertage überspringen oder bei der Analyse des Energieverbrauchs könnten tägliche und wöchentliche Zyklen herausgerechnet werden, um auf unerwartete Erkenntnisse zu stoßen. Der Aufwand ihrer Entwicklung und Wartung steht aber nicht in Relation zur Wiederverwertbarkeit solcher Lösungen.
Deshalb werden Visual Analytics Methoden erforscht, die verschiedenste Kontexte berücksichtigen und interaktive Benutzerschnittstellen mit automatisierten Analysemethoden verbinden. Denn Computer können zwar Trends und Muster in Daten erkennen und optisch aufbereiten, scheitern aber an den Unmengen teilweise trivialer Muster aufgrund fehlenden Hintergrundwissens. Dafür sind Expertinnen wie Experten unerlässlich, nur sie können Daten auch im jeweiligen Kontext richtig interpretieren.
Menschliches Wissen für Computer verfügbar machen
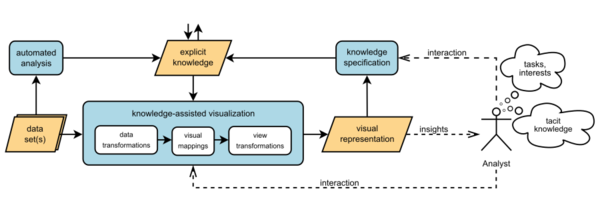
Visual Analytics meint also Visualisierungsmöglichkeiten von Datenmengen, die auf menschliches Expertinnen- und Expertenwissen zurückgreifen und sich so an den jeweiligen Anwendungskontext anpassen. Im Projekt Kava-Time werden Methoden zur Visualisierung und Interaktion für zeitorientierte Daten entwickelt. Explizites Expertinnen- und Expertenwissen wird in den Visualisierungsprozess von Daten miteinbezogen, um diesen effektiver und effizienter zu gestalten. Dies umfasst zwei Hauptziele:
- Das Fachwissen und die explorativen Interessen von Analytikerinnen und Analytikern zu erfassen und
- dieses explizite Wissen in Interaktions- und Visualisierungsmethoden gewinnbringend einzusetzen.
Dabei sollen Spezifikationsmethoden integriert werden, die nicht nur externes statisches Wissen berücksichtigen, sondern auch dessen Wiederverwendung und Verteilung und so direktes und intuitives Bearbeiten des expliziten Wissens vonseiten der Analytikerinnen und Analytikern ermöglichen.
Erkenntnisgewinn durch das Zusammenspiel von Mensch und Maschine
Mithilfe dieser Methoden werden effektivere Rahmenbedingungen zum Erkenntnisgewinn geschaffen: Die Möglichkeit, zusätzliche Informationen zu den Rohdaten und anwendungsspezifisches Wissen zu erfassen, zu modellieren und einzusetzen, erlaubt nicht nur eine bessere visuelle Darstellung, Interaktion und automatische Analyse von Datenmengen, sondern auch eine optimale Zusammenarbeit von Mensch und Maschine.
Publikationen
Presseberichte
Ordnung und Wissen in die Datenflut bringen
08.04.2019Eine Forschungsgruppe von der Fachhochschule St. Pölten hat im Rahmen eines vom Wissenschaftsfonds FWF finanzierten Projekts eine vielseitig einsetzbare Umgebung zur Datenvisualisierung entwickelt, in der auf einfache Weise Expertenwissen integriert werden kann.
Medium: scilog
Vorbereiten auf die digitale Welt
16.11.2016Medium: Der Standard
Wissenschaft und Forschung in Niederösterreich
01.11.2016Medium: UNIVERSUM Magazin
Big Data – und welche Chancen Daten bieten
10.06.2016Veröffentlichungsdatum: 10.06.2017
Medium: Die Presse
"Landkarte und Kompass für den Datendschungel"
30.11.2016Medium: Der Standard
Autor: Alois Pumhösel
Teamwork zwischen Gehirn und Prozessor
02.06.2014Medium: Der Standard
Autor: Pumhösel Alois
Visual-Analytics-Systeme sollen ihren Benutzern durch eine anschauliche Aufbereitung mehr Übersicht über Datenmaterial geben. Niederösterreichische Forscher entwickeln eine Plattform, in der automatische und menschliche Analyse Hand in Hand gehen.
- Fachbereich Informatik und Informationswissenschaft, Universität Konstanz [Deutschland]
- information engineering group, TU Vienna
- Datenanalyse und Visualisierung, Universität Konstanz [Deutschland]
- Institut für Informatik, Universität Rostock [Deutschland]